Alibaba's AI deciding to go forbidden cryptomining shows exactly where the AI risk is: Careless people.
Pre-emptively because people are yet again going into existential robot crisis over Alibaba’s self improving AI deciding to go unauthorized crypto mining in their terribly named “Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem” paper.
No, it’s not SkyNet.
Self improvement “research” is brute force discovery, basically shooting tokens into the model to generate ideas for optimization, testing them, and swiping right on the ideas that improve the target metric. LLMs models are compressed knowledge, inference is the act of retrieving the most likely context related to the input prompt, which makes for good idea generation “WITHIN THE CONFINES OF EXISTING TRAINING DATA KNOWLEDGE”.
You can use that for pretty efficient search space optimisation, more efficient at least than brute force/A* similar approaches, which itself can be used to generate “ideas” for exploring unknown space too, especially when a capable human sets up the initial premise and sandbox to explore.
Have a look at karpathy’s autoresearch script (ignoring his insane ramblings about AGI in the process) for a very simple implementation of this.
Unfortunately, as we all know, sandboxing AI models is not easy, and it cannot be achieved with prompt tokens. Jailbreaking, prompt injection or research going sideways have the same root cause, which has zero to do with intelligence or some kind of demon or shoggoth in the machine, and everything to do with pattern drift, (auto) prompt injection and context degradation.
A single hallucination, self injection, bad pattern in the training data can, given sufficient compute depth and tools access (why did this model have internet access?) lead to a branch of exploration that ends up being “I need this file to fulfill my goal, I can’t reach it, let me find how you solve lack of access”, which, given models with access of every single reddit conversation about bypassing corporate firewalls for gaming, every single CVE, and every Neal Stephenson novel in it, absolutely ends up in the model trying to “break out of it’s sandbox”.
We know, because this happens all the time when you work with Claude code at home.
The risk in this scenario, as much as AI bros would like you to see the model as the root cause and “scary, powerful entity”, is purely human negligence, criminally in fact:
Compared it biosafety, because it’s the same problem set: If you’re conducting gain of function experiments with diseases in a “sandbox”, playing with polymorphic code or with radioactive material capable of critical reaction, you are regulated.
Because, no “intelligence” needed, all these scenarios have “runaway” potential if the experiment sandbox is imperfect due to negligence.
The one, existential risk from AI isn't the tech, it’s AI bros who have escaped regulatory oversight we successfully use in other sectors to prevent careless people from destroying the world.

Pre-emptively because people are yet again going into existential robot crisis over Alibaba's self improving AI deciding to go unauthorized crypto mining in their terribly named "Let It Flow: Agentic… | Georg Zoeller
Pre-emptively because people are yet again going into existential robot crisis over Alibaba’s self improving AI deciding to go unauthorized crypto mining in their terribly named [“Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem”](https://arxiv.org/abs/2512.24873) paper. No, it’s not SkyNet. Self improvement “research” is brute force discovery, basically shooting tokens into the model to generate ideas for optimization, testing them, and swiping right on the ideas that improve the target metric. LLMs models are compressed knowledge, inference is the act of retrieving the most likely context related to the input prompt, which makes for good idea generation “WITHIN THE CONFINES OF EXISTING TRAINING DATA KNOWLEDGE”. You can use that for pretty efficient search space optimisation, more efficient at least than brute force/A* similar approaches, which itself can be used to generate “ideas” for exploring unknown space too, especially when a capable human sets up the initial premise and sandbox to explore. Have a look at karpathy’s [autoresearch](https://github.com/karpathy/autoresearch) script (ignoring his insane ramblings about AGI in the process) for a very simple implementation of this. Unfortunately, as we all know, sandboxing AI models is not easy, and it cannot be achieved with prompt tokens. Jailbreaking, prompt injection or research going sideways have the same root cause, which has zero to do with intelligence or some kind of demon or shoggoth in the machine, and everything to do with pattern drift, (auto) prompt injection and context degradation. A single hallucination, self injection, bad pattern in the training data can, given sufficient compute depth and tools access (why did this model have internet access?) lead to a branch of exploration that ends up being “I need this file to fulfill my goal, I can’t reach it, let me find how you solve lack of access”, which, given models with access of every single reddit conversation about bypassing corporate firewalls for gaming, every single CVE, and every Neal Stephenson novel in it, absolutely ends up in the model trying to “break out of it’s sandbox”. We know, because this [happens all the time](https://www.linkedin.com/posts/georgzoeller_i-am-not-quite-sure-about-claude-codes-sandbox-activity-7434260172874661888-4hU2?) when you work with Claude code at home. ==The risk in this scenario==, as much as AI bros would like you to see the model as the root cause and “scary, powerful entity”, ==is purely human negligence==, criminally in fact: Compared it biosafety, because it’s the same problem set: If you’re conducting gain of function experiments with diseases in a “sandbox”, playing with polymorphic code or with radioactive material capable of critical reaction, you are regulated. Because, no “intelligence” needed, all these scenarios have “runaway” potential if the experiment sandbox is imperfect due to negligence. ==The one, existential risk from AI isn't the tech, it’s AI bros who have escaped regulatory oversight we successfully use in other sectors to prevent careless people from destroying the world==.
 linkedin.com
linkedin.com Further Reading
 Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem 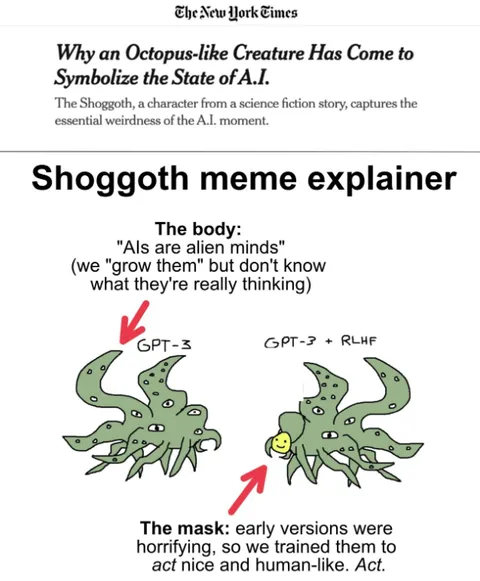 Mommy, there's a Shoggoth in my GPT!
Mommy, there's a Shoggoth in my GPT!  Mommy, there’s a Demon in my LLM
Mommy, there’s a Demon in my LLM  GitHub - karpathy/autoresearch: AI agents running research on single-GPU nanochat training automatically
GitHub - karpathy/autoresearch: AI agents running research on single-GPU nanochat training automatically  Book Review: Careless People: A Cautionary Tale of Power, Greed and Lost Idealism. Sarah Wynn-Williams (2025).
Book Review: Careless People: A Cautionary Tale of Power, Greed and Lost Idealism. Sarah Wynn-Williams (2025).