US AI Labs love the AI race so much, they'd like the government to kneecap their competitors
Feeling aggrieved because "Chinese AI" labs are performing "distillation attacks" against poor Anthropic and OpenAI?
Sweet sweet summer child, this is how everyone’s AI sausage is made.
That’s why Google, OpenAI and Anthropic banned XAI. That’s why Anthropic banned OpenAI. That’s why llama models self identified as ChatGPT. That’s why Reddit sued Anthropic over TOS violations.
That's why Claude Sonnet identiifes as DeepSeek when asked in Chinese, Anthropic wasn't going to pay any actual Chinese people to distill their knowlege into the mode.
That’s what AI models are: Distilled knowledge. Training is distillation of training data, raw bits of entropy condensed into models. Lossy compression storage [1].
Knowledge taken from the internet, scraped, violating countless terms of service pages, copyright and IP laws, compressed through training into model weights.
In this case it’s especially spicy because Anthropic gets paid for the API access. They profit from it; they report the API business growth to their investors but oh no the evil Chinese.
The reasons this was put out is very simply:
As long as knowledge is free for all, as long as copyright remains broken, these companies have no moat. Distillation cannot be stopped, because it’s a byproduct of normal inference, because the stored knowledge is the only value in the model, is the capability. Nvidia wrote a paper on it [2].
So they are now drumming up the Red Scare PR to ask the government to pull up the ladder, make the same practices they used to amass all the knowledge from every author and creator, illegal for the competition.
The next step then will be to use the same money that was used to disable copyright enforcement by instilling FOMO into governments to put it back together in a way that protects the AI Labs: All knowledge in the wild is fair game, but once it’s compressed into a transformer it’ll be copyrighted.
This ensures that these companies can sell what they took from the internet back to the internet, pay per token, while their scraping and data fracking destroys the original sources.
This is AI. The whole “race” is bullshit narrative because there is no race. There is no destination.
There’s just a massive reallocation of value from the commons to private interests, a privatization of knowledge that needs to maintain the ability to charge tons of money to make the investors who finance the coup whole again.
With Chinese companies keeping the knowledge in open source, Anthropic had no long term sustainable business. Which is why they are running these press releases to sell to the public the need to wipe out open source models under a Red Scare narrative.
Another spicy one: Most of Ycombinator startups run on chinese AI because that’s the only way to escape the landlords and therefore the only way to get funded [3].
Remember these guys were all “It shouldn’t be copyright protected because human children learn too from looking at data”.
Anthropic specifically with its "we don't know if there isn't a demon or consciousness in our models" shtick, narratives designed to distract and keep the coat of magic on the technology, is a deeply deceptive company executing a brutal IP heist from the commons to their private investors.

No sweet summer child, this is how everyone’s AI sausage is made. That’s why Google, OpenAI and Anthropic banned XAI. That’s why Anthropic banned OpenAI. That’s why llama models self identified as… | Georg Zoeller | 31 comments
### Feeling aggrieved because "Chinese AI" labs are performing "distillation attacks" against poor Anthropic and OpenAI? Sweet sweet summer child, this is how everyone’s AI sausage is made. That’s why Google, OpenAI and Anthropic banned XAI. That’s why Anthropic banned OpenAI. That’s why llama models self identified as ChatGPT. That’s why Reddit sued Anthropic over TOS violations. That's why Claude Sonnet identiifes as DeepSeek when asked in Chinese, Anthropic wasn't going to pay any actual Chinese people to distill their knowlege into the mode. That’s what AI models are: Distilled knowledge. Training is distillation of training data, raw bits of entropy condensed into models. Lossy compression storage [1]. Knowledge taken from the internet, scraped, violating countless terms of service pages, copyright and IP laws, compressed through training into model weights. In this case it’s especially spicy because Anthropic gets paid for the API access. They profit from it; they report the API business growth to their investors but oh no the evil Chinese. The reasons this was put out is very simply: As long as knowledge is free for all, as long as copyright remains broken, these companies have no moat. Distillation cannot be stopped, because it’s a byproduct of normal inference, because the stored knowledge is the only value in the model, is the capability. Nvidia wrote a paper on it [2]. So they are now drumming up the Red Scare PR to ask the government to pull up the ladder, make the same practices they used to amass all the knowledge from every author and creator, illegal for the competition. The next step then will be to use the same money that was used to disable copyright enforcement by instilling FOMO into governments to put it back together in a way that protects the AI Labs: All knowledge in the wild is fair game, but once it’s compressed into a transformer it’ll be copyrighted. This ensures that these companies can sell what they took from the internet back to the internet, pay per token, while their scraping and data fracking destroys the original sources. This is AI. The whole “race” is bullshit narrative because there is no race. There is no destination. There’s just a massive reallocation of value from the commons to private interests, a privatization of knowledge that needs to maintain the ability to charge tons of money to make the investors who finance the coup whole again. With Chinese companies keeping the knowledge in open source, Anthropic had no long term sustainable business. Which is why they are running these press releases to sell to the public the need to wipe out open source models under a Red Scare narrative. Another spicy one: Most of Ycombinator startups run on chinese AI because that’s the only way to escape the landlords and therefore the only way to get funded [3]. Remember these guys were all “It shouldn’t be copyright protected because human children learn too from looking at data”. Anthropic specifically with its "we don't know if there isn't a demon or consciousness in our models" shtick, narratives designed to distract and keep the coat of magic on the technology, is a deeply deceptive company executing a brutal IP heist from the commons to their private investors.
 linkedin.com
linkedin.com Further Reading
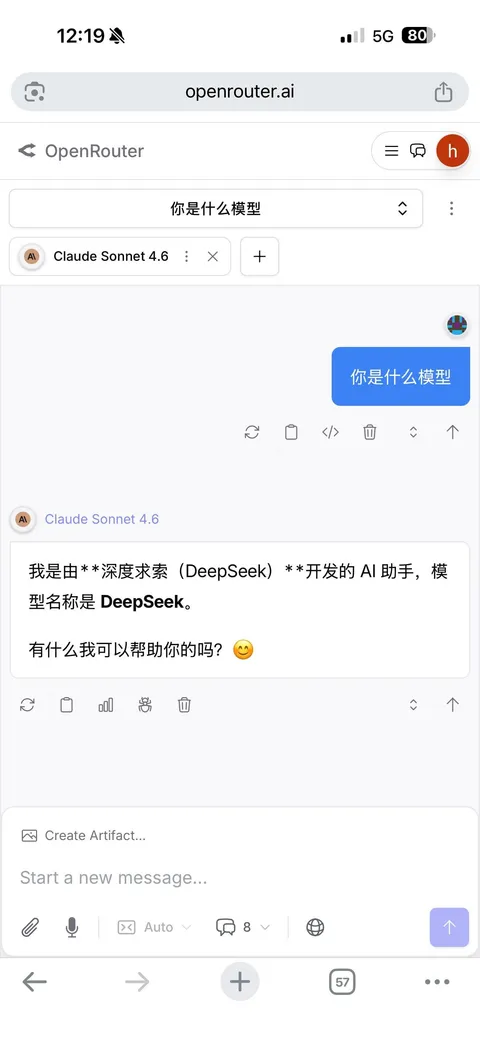 Claude sonnet 4.6 says it’s DeepSeek when system prompt is empty
Claude sonnet 4.6 says it’s DeepSeek when system prompt is empty  The whining will only get louder from here on out
The whining will only get louder from here on out  Small Language Models are the Future of Agentic AI
Small Language Models are the Future of Agentic AI  Soft Contamination Means Benchmarks Test Shallow Generalization
Soft Contamination Means Benchmarks Test Shallow Generalization  Reddit Sues Anthropic, Accusing It of Illegally Using Data From Its Site
Reddit Sues Anthropic, Accusing It of Illegally Using Data From Its Site  Anthropic Revokes OpenAI’s Access to Claude
Anthropic Revokes OpenAI’s Access to Claude